hal0-api
A FastAPI application that binds 0.0.0.0:8080. It serves the REST control
plane under /api/*, the OpenAI-compatible inference surface under
/v1/*, the MCP servers under /mcp/*, and the built dashboard at /.
hal0 is a single self-hosted service that turns one machine into an OpenAI-compatible inference platform. Everything runs behind one process — hal0-api — which owns configuration, model and slot lifecycle, request routing, and the web UI. Understanding how those parts relate is the key to understanding the rest of these docs.
hal0-api
A FastAPI application that binds 0.0.0.0:8080. It serves the REST control
plane under /api/*, the OpenAI-compatible inference surface under
/v1/*, the MCP servers under /mcp/*, and the built dashboard at /.
Slots
Each slot is one model served by one podman container, managed through a
hal0-slot@<name>.service systemd unit. The SlotManager owns their
lifecycle and state.
Dispatcher
The registry-aware router that resolves every incoming /v1 request to a
slot or an external upstream, then forwards it — wrapping the slot in its
serving state for the duration of the call.
Front ends
The React dashboard (served by hal0-api itself) for operating the platform,
plus optional OpenWebUI as a chat front end pointed at the /v1 surface.
The application is built once in create_app() and exposes a clearly grouped
surface area:
/v1/* — the OpenAI-compatible inference API. The model-listing probe
(GET /v1/models) is intentionally separate from the inference writer
surface, because OpenAI clients commonly list models before sending an
Authorization header./api/* — the operator control plane: slots, models, capabilities,
profiles, providers, hardware, health, settings, activity, updates, and more./mcp/admin and /mcp/memory — Model Context Protocol servers
mounted as sub-applications so agents and tools can drive hal0 directly./ — the built dashboard SPA, mounted last so it never shadows an API
route. Any unmatched non-API path falls back to the SPA’s index.html so
client-side routing survives a reload.When hal0-api starts, its lifespan wires the long-lived objects together: the
model registry, the upstream registry, the SlotManager, the Dispatcher, the
hardware probe, the capability orchestrator, and an event bus that streams
state changes to the dashboard footer. These are shared across all requests —
the API is a thin layer over them.
A slot is a named, long-lived place to serve one model. Behind each slot is
a single podman container started by a hal0-slot@<name>.service systemd unit
whose ExecStart runs podman run. The SlotManager drives every transition
through an explicit state machine and persists it so the dashboard reflects real
lifecycle events, not systemd snapshots.
Slots are the unit hal0 reasons about everywhere: the dispatcher routes to them, the GPU arbiter coordinates exclusive GPU access between them, and capabilities and profiles describe how to configure them. The Slots concept covers the lifecycle, single-flight dispatch, and the GPU arbiter in depth.
The Dispatcher reads the model registry and the list of upstreams to decide
where each OpenAI-compatible request goes. It never starts or stops slots
itself; it resolves a target, gates on readiness, and forwards. Resolution runs
in a fixed order so behaviour is predictable:
Container-slot preemption — a loaded container slot is the authoritative server for the models it advertises, so it wins over any default registry binding.
Registry lookup — an exact model-to-upstream binding from the registry. If that upstream is online, forward there.
Passthrough — any upstream whose cached /v1/models already advertises
the requested model id.
Cold-cache prefetch — fan out /v1/models against external upstreams
with empty caches (coalesced so concurrent identical prefetches share one
call), then re-check passthrough.
Capability / path routing — last-resort heuristics: /embeddings →
the embed slot, /audio/speech → the TTS slot, /images/generations → the
image slot, an FLM name:tag model → the NPU slot, and explicit slot-name
addressing. Falls back to the chat slot.
Every routing decision emits one structured log line, so you can always see why a request went where it did.
A client POSTs to /v1/chat/completions with a model field — that can
be a model id, or a slot alias such as chat or agent.
The route layer translates a slot alias to the slot’s configured model id,
then asks the dispatcher to resolve the request to an UpstreamCall.
If the target is a local slot whose model isn’t loaded yet, the dispatcher
kicks a backend-aware load so the slot’s declared device and profile pick
the runtime — then gates on readiness. A slot that is still loading returns a
structured slot.loading 503 with a Retry-After hint instead of a raw
connection error.
Once the slot is ready, the dispatcher forwards the request, wrapping the slot in its serving state for the lifetime of the call. For a streamed response, that state is held open until the stream drains.
The upstream’s response (including streamed SSE chunks and any error envelope) is passed back to the client verbatim.
hal0-api serves the dashboard itself — a React single-page application. There is no separate web server to run. The dashboard is where you create and operate slots, pull models, pick capabilities, watch live activity, and configure the platform.
For end-user chat, point OpenWebUI (or any OpenAI-compatible client) at
hal0’s /v1 surface. Because hal0 speaks the OpenAI API, anything that talks to
OpenAI talks to hal0.
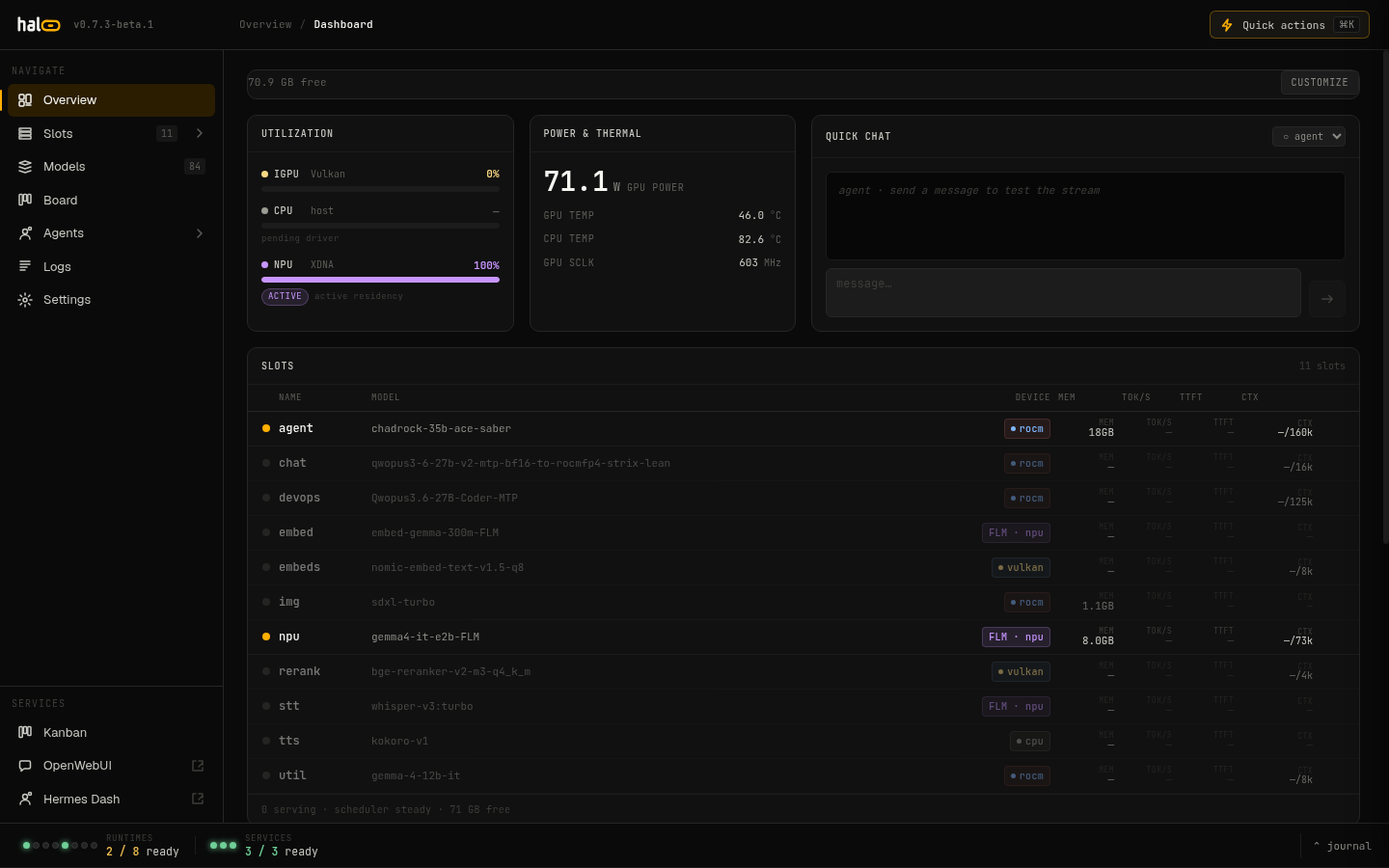 The hal0 dashboard — slot cards, live activity, and hardware metrics in one view.
The hal0 dashboard — slot cards, live activity, and hardware metrics in one view.