Capabilities & profiles
Three distinct ideas shape every slot in hal0, and keeping them separate is what makes the system tractable: capabilities describe what you want a slot to do, profiles describe how it runs, and the device describes where it runs. They compose — a capability points at a slot, the slot picks a profile, and the profile is keyed to a device.
Capabilities: what a slot does
Section titled “Capabilities: what a slot does”A capability is an overlay the dashboard uses to group related slots under one operator-friendly idea. Rather than make you hand-configure each underlying slot, you pick a capability and its child, and hal0 reconciles the real slot for you. The capability groups are:
| Capability | Children → underlying slot |
|---|---|
embed | embed → embed, rerank → embed-rerank |
voice | stt → stt, tts → tts |
img | img → img |
vision | vision → vision |
Chat is deliberately not a capability group — it lives in the dedicated chat slot and is configured directly, not through the capability overlay.
The selected capabilities are stored in capabilities.toml. When you apply a
change, the orchestrator computes one atomic change set across both
capabilities.toml and the affected slot TOML — they’re written together so the
two can never drift mid-apply — and only then drives the slot lifecycle:
turning a capability on loads its slot, turning it off unloads it, and changing
the model or backend swaps it. On first boot, hal0 seeds capabilities.toml
from whatever the slots already declare, so the overlay reflects reality
immediately.
Profiles: how a slot runs
Section titled “Profiles: how a slot runs”A profile is a reusable container-runtime template. It bundles the container image, a set of bench-tuned launch flags, and an MTP (speculative decoding) toggle. A slot references a profile by name; the profile supplies everything about how to run except the model, context size, and port — those belong to the slot. This split means many slots can share one tuned profile, and you can re-tune a profile once for every slot that uses it.
hal0 ships seed profiles so a fresh install is immediately usable:
| Profile | Targets | Purpose |
|---|---|---|
rocm | GPU (ROCm) | MoE / agent models, FP4, no MTP (larger q8 KV) — the gpu-rocm default |
rocm-dnse | GPU (ROCm) | Dense models with MTP speculative decoding (q4 KV) |
rocm-moe | GPU (ROCm) | MoE models with MTP speculative decoding (q4 KV) |
vulkan | GPU (Vulkan) | Standard Vulkan path and fallback |
flm | NPU | FLM inference on the NPU |
tts | CPU | Text-to-speech (Kokoro) |
comfyui | image | Image generation (ComfyUI) |
If profiles.toml is absent, these seeds are returned as the catalog, so the
profile API is always populated. Seed profiles are immutable — to customise one,
clone it under a new name and edit the copy. Each profile is also classified
into a runtime family (llama-server, FLM, Kokoro, or ComfyUI) that determines
which slot types it can serve.
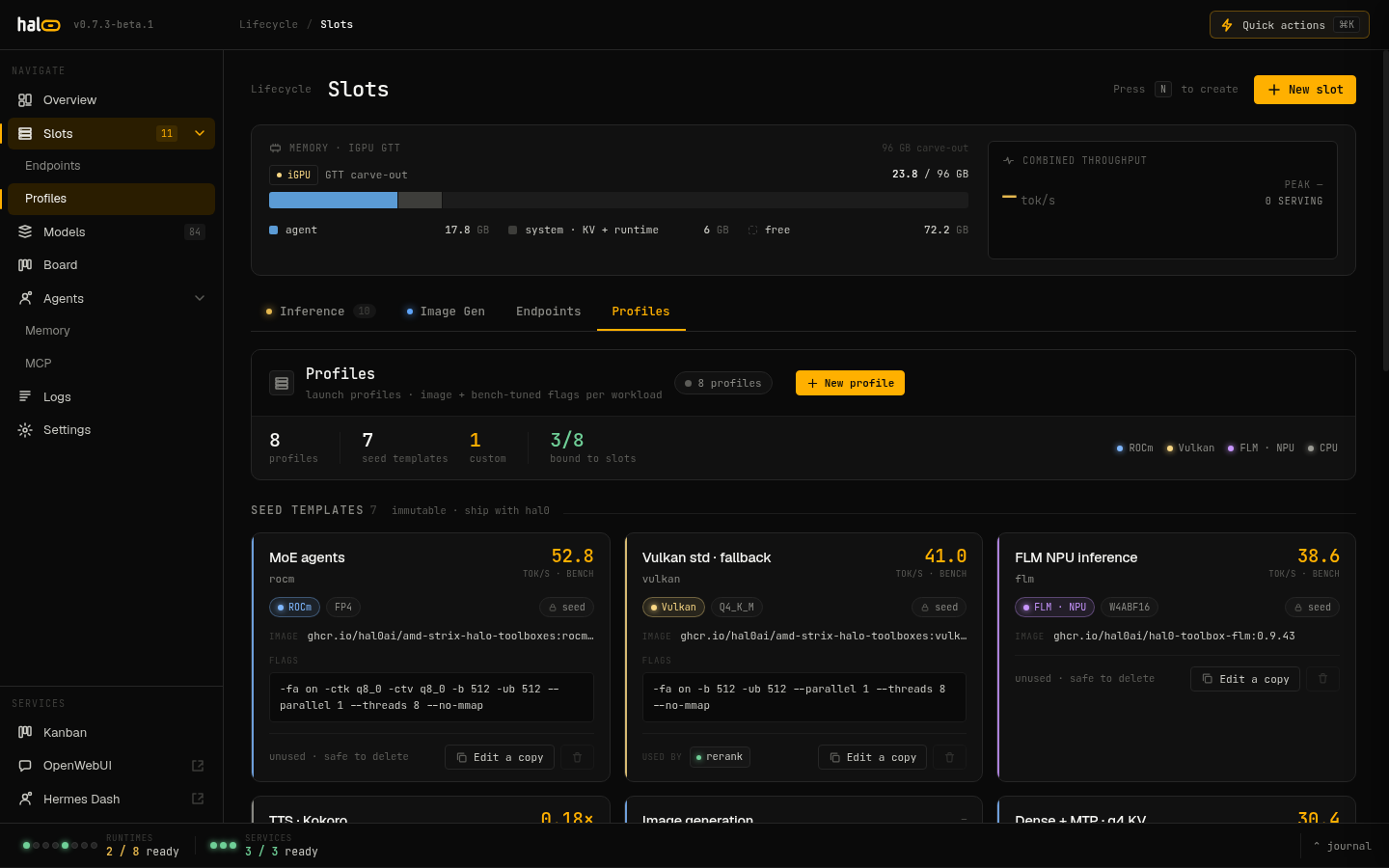
The Profiles tab — seed profile cards with bench metrics, device class chips, and the clone affordance for creating custom profiles.
Device and backend: where a slot runs
Section titled “Device and backend: where a slot runs”The device is a slot’s hardware-preference field. It carries hardware intent only — not a provider choice — and is validated at config-load time so a typo fails fast. The valid devices are:
gpu-rocm— the AMD iGPU via ROCm.gpu-vulkan— a GPU via Vulkan (the broad-compatibility path).cpu— CPU-only execution.npu— the AMD XDNA NPU via FastFlowLM.
device replaced an older overloaded backend field that mixed hardware and
provider identity. Legacy configs that still set backend are auto-promoted to
a device on load (with a deprecation warning), so old slot TOMLs keep working.
Device-to-profile defaults and coherence
Section titled “Device-to-profile defaults and coherence”Each device has a default profile, used by the create-slot picker and by migration:
| Device | Default profile |
|---|---|
gpu-rocm | rocm |
gpu-vulkan | vulkan |
cpu | tts |
npu | flm |
Because a slot carries both a device and a profile, the two must stay
coherent — a gpu-vulkan device paired with a ROCm profile would be a
contradiction. hal0 reconciles them when a slot is created or updated so the
reported backend follows the device, and the seed profiles above are the
starting point that keeps a fresh slot consistent.
The NPU trio
Section titled “The NPU trio”The AMD XDNA NPU is driven by FastFlowLM (FLM), and one detail shapes how hal0
uses it: a single flm serve process serves three modalities at once —
chat, speech-to-text, and embeddings. hal0 calls this the NPU trio.
There is one containerized NPU slot. Its chat role routes through the slot’s
upstream like any other slot. The other two modalities ride as shadow slots
— stt and embed — whose requests are posted straight to the same
container’s port when their slot records are enabled. There’s no second process
and no separate model server: the three endpoints are the same FLM process
answering on one static port.
Because the XDNA hardware context admits only one NPU LLM at a time, hal0
enforces NPU exclusivity: you can’t enable a second device=npu chat slot. When
the NPU container isn’t dispatchable, trio requests degrade with a clear
npu.trio_unavailable error rather than failing obscurely.