OpenAI-compatible API
hal0 exposes an OpenAI-compatible surface under /v1, served by hal0-api on
port 8080. Drop the base URL into any OpenAI-shaped client (OpenWebUI,
official SDKs, third-party tools) and it works unmodified.
http://localhost:8080/v1Each POST endpoint parses the JSON body, resolves an upstream via the dispatcher, and forwards the request. Streaming (SSE for chat/completions, binary for audio speech) and non-streaming responses are both handled by the forwarder.
Endpoints
Section titled “Endpoints”| Method | Path | Purpose |
|---|---|---|
| GET | /v1/models | List all models advertised across every configured upstream, plus per-slot aliases and virtual hal0/* names. |
| GET | /v1/models/{id} | Look up one model from the aggregated catalog. |
| POST | /v1/chat/completions | Chat completion. Supports streaming and the optional omni tool-calling loop. |
| POST | /v1/completions | Legacy text completion. |
| POST | /v1/embeddings | Text embeddings (routes to the NPU FLM trio when an embed-NPU slot is targeted). |
| POST | /v1/rerankings | Document reranking. |
| POST | /v1/audio/transcriptions | Speech-to-text. Multipart upload; the model field is required. |
| POST | /v1/audio/speech | Text-to-speech. The model field is required. |
| POST | /v1/images/generations | Image generation via the ComfyUI provider. |
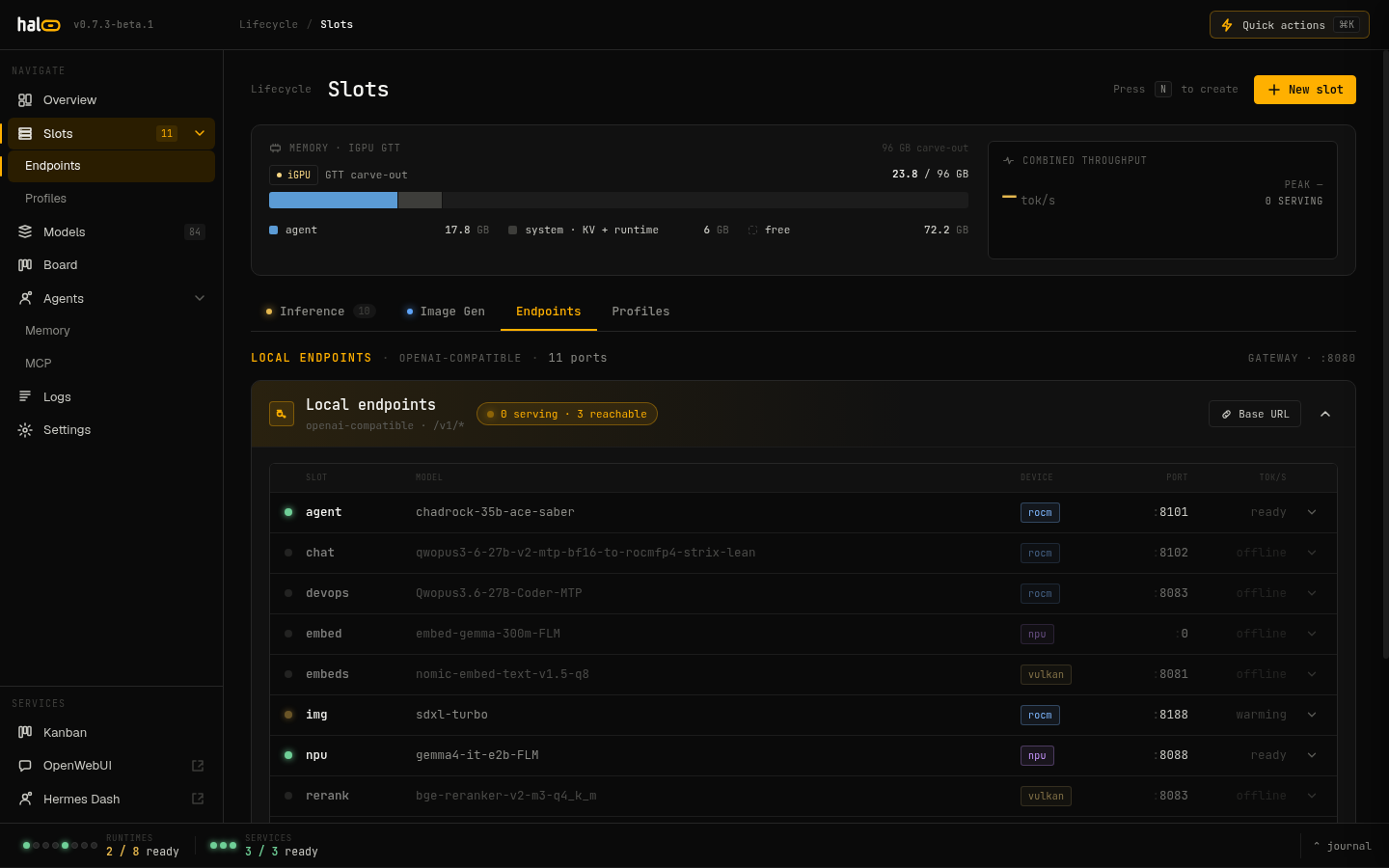 Dashboard Endpoints tab — live status for every /v1 route.
Dashboard Endpoints tab — live status for every /v1 route.
GET /v1/models
Section titled “GET /v1/models”Returns the OpenAI listing shape:
{ "object": "list", "data": [ /* model objects */ ] }The list combines three kinds of entries:
- Per-slot alias entries — every enabled, currently-served chat slot
(
type == "llm") appears once, withidequal to the slot alias (the slot name, e.g.chat), a humanname, and the slot’scontext_length. Unloaded/disabled slots are omitted. - Upstream catalog entries — the raw model ids each
advertise_modelsupstream reports, so non-chat models (embed, rerank, image) keep their direct-addressing ids. - Virtual
hal0/*names — the canonical live-resolve names so clients can pin a role rather than a model. Each carriescontext_lengthand a_hal0metadata block describing what it resolves to.
POST /v1/chat/completions
Section titled “POST /v1/chat/completions”The standard OpenAI chat body. hal0 adds two opt-in behaviours:
- The
modelfield may be a slot name or alias instead of a model id — it is rewritten to the backing model before routing. See Slot as model. "omni": trueopts the request into the client-side tool-calling loop when the resolved chat slot’s model advertises tool-calling. The field is stripped before forwarding so strict upstreams never see it.
curl http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "chat", "messages": [ {"role": "user", "content": "Say hello in one word."} ] }'curl http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "chat", "stream": true, "messages": [ {"role": "user", "content": "Stream a short greeting."} ] }'POST /v1/embeddings
Section titled “POST /v1/embeddings”Standard OpenAI embeddings body. When the request resolves to an enabled NPU
embedding slot and the FLM chat anchor is loaded, hal0 posts straight to the
FLM child’s /v1/embeddings; otherwise it dispatches normally.
POST /v1/audio/transcriptions
Section titled “POST /v1/audio/transcriptions”A multipart/form-data upload. The model form field is required —
omitting it returns a 400 (request.missing_model) rather than a confusing
404. The raw multipart bytes are forwarded verbatim so the upstream’s own
parser reads the audio. NPU stt-npu slots route directly to the FLM child.
POST /v1/audio/speech
Section titled “POST /v1/audio/speech”JSON body: {"model": "...", "input": "...", "voice": "..."}. The model
field is required (a missing model returns 400, request.missing_model). The
response is the synthesised audio stream.
POST /v1/images/generations
Section titled “POST /v1/images/generations”OpenAI-shaped image generation, translated to a ComfyUI workflow by hal0.
Request (honoured subset):
{ "model": "sdxl-turbo", "prompt": "a cat in a hat", "n": 1, "size": "1024x1024", "response_format": "url"}prompt is required; model must be a curated image model (built-ins:
sdxl-turbo, sd-1.5-pruned-emaonly). Optional hal0 extra_body knobs:
seed, steps, cfg, negative_prompt.
Response:
{ "created": 1716000000, "data": [ { "url": "/api/images/cache/<uuid>.png" } ], "_hal0": { "...": "workflow debug meta" }}With response_format: "b64_json" each entry carries a b64_json field
instead of a cache url. Image generation flips the GPU into exclusive image
mode via the arbiter (unloading LLM GPU slots), so the first image request may
take longer while the img slot loads.
Related references
Section titled “Related references”- Slot as model — addressing slots by name in the
modelfield. - hal0 CLI — manage the slots these endpoints route to.
- First chat — a guided walkthrough.