Generate images
hal0 generates images through ComfyUI, a node-graph Stable-Diffusion
runtime. It runs as one containerized generation engine — a single
run loads many cooperating models at once — using the
kyuz0 Strix Halo ComfyUI image
(docker.io/kyuz0/amd-strix-halo-comfyui), tuned for the AMD iGPU.
Because there is exactly one iGPU, image generation is mutually exclusive with the LLM stack: only one of them can hold GPU memory at a time. hal0 models this as a switchover driven by the GPU arbiter — the ComfyUI container stays resident, only its model memory is freed and reloaded.
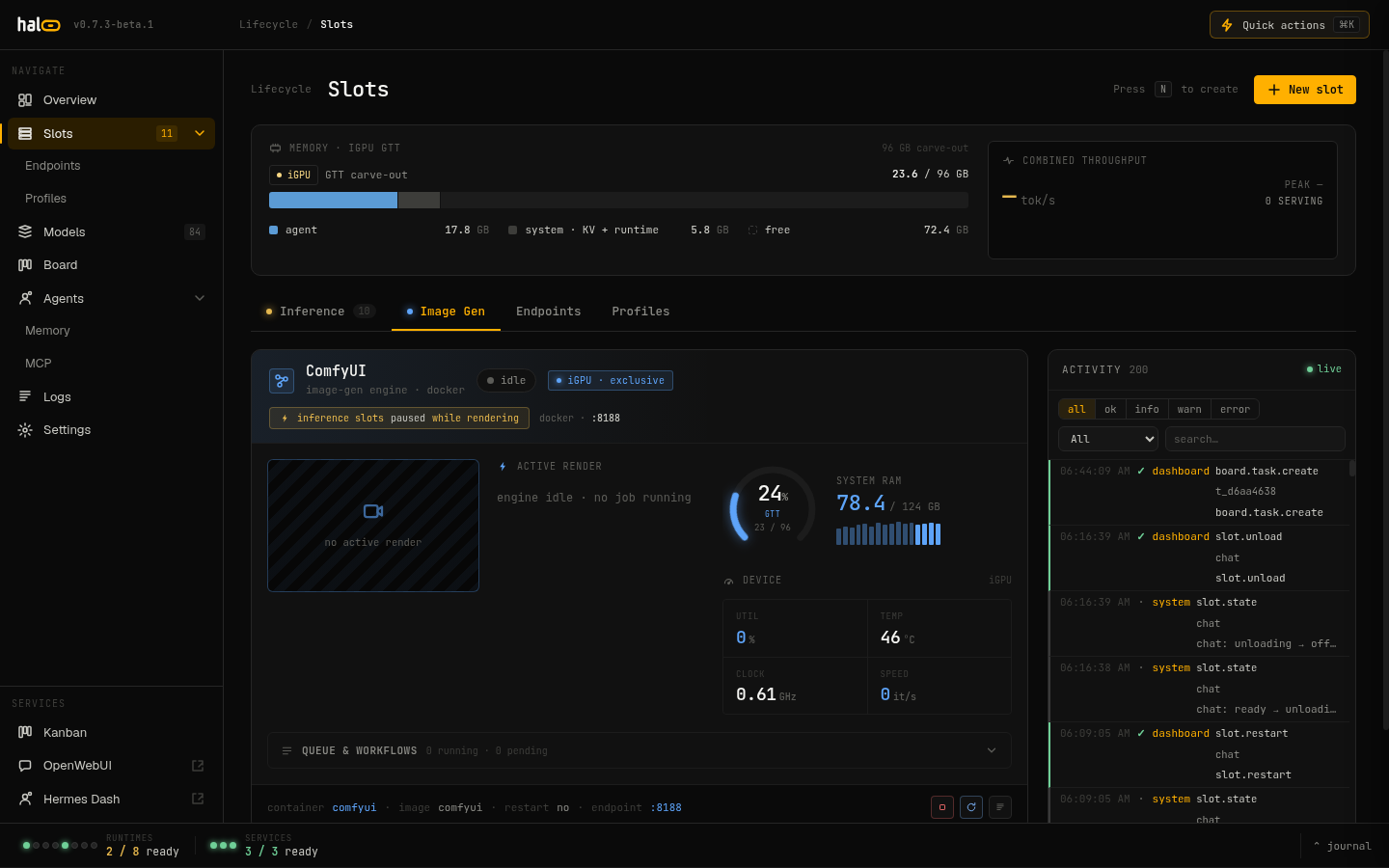 The Image-Gen tab: engine state, GPU memory gauges, queue, and switchover controls.
The Image-Gen tab: engine state, GPU memory gauges, queue, and switchover controls.
Read the generation-engine status
Section titled “Read the generation-engine status”The dashboard’s Image-Gen tab renders from a read-only aggregator that folds container state, the LLM-owner check, and ComfyUI’s own HTTP API into one object:
curl http://localhost:8080/api/comfyui/statusKey fields:
mode—generation(ComfyUI owns the iGPU) orinference(the LLM stack owns it). The GPU arbiter is the source of truth.engine—running,generating(a render is in flight),starting(container up, port not bound yet), orstopped.reachable— whether ComfyUI’s HTTP API answers.container— theimgslot container’s state (running/exited/absent).memory— GTT and RAM gauges from ComfyUI’s/system_stats.queue—{running, pending}job counts.switchover— the in-flight switch tracker (active,target,error) so a poll can render “switching…”.
Every probe degrades to a safe default: a dead engine surfaces as
stopped, never a 500.
Switch the iGPU between modes
Section titled “Switch the iGPU between modes”The img slot runs as the hal0-slot@img.service systemd unit. To hand
the iGPU to ComfyUI (drains and unloads the LLM GPU slots, then ensures
the resident container is up):
curl -X POST http://localhost:8080/api/comfyui/switchover \ -H 'Content-Type: application/json' \ -d '{"mode": "generation"}'To hand it back to inference (frees ComfyUI’s models via ComfyUI’s own free path — the container and web UI stay up — then reloads the saved LLM slots):
curl -X POST http://localhost:8080/api/comfyui/switchover \ -H 'Content-Type: application/json' \ -d '{"mode": "inference"}'Body fields:
| Field | Type | Notes |
|---|---|---|
mode | string | generation or inference (required). |
force | bool | Switching to inference drops any running/pending render. Without force, a busy queue is refused with 409. |
pin | bool | generation only — hold image mode against the arbiter’s idle-restore. |
Responses: 202 (switching, runs in the background — poll the
switchover block on /status), 200 (noop, already in the target
mode), 409 (switch already in flight, or a busy queue without
force), 503 (comfyui.arbiter_unavailable — the GPU arbiter is not
wired on this host).
Pin or unpin image mode independently:
curl -X POST http://localhost:8080/api/comfyui/pin \ -H 'Content-Type: application/json' \ -d '{"pinned": true}'Enable the switchover
Section titled “Enable the switchover”Both write paths (/switchover and /pin) require the GPU arbiter to be
wired — that is, hal0-api must be running with a configured img slot so
the slot manager attaches the arbiter at startup. Without it both endpoints
return 503 (comfyui.arbiter_unavailable). See
Manage slots for how to add and enable the
img slot.
Generate an image
Section titled “Generate an image”The OpenAI-compatible endpoint translates your request into a ComfyUI workflow, runs it, and returns the result in OpenAI’s shape. The route flips the GPU to image mode before dispatching, so a single call also performs the switchover when needed.
curl -X POST http://localhost:8080/v1/images/generations \ -H 'Content-Type: application/json' \ -d '{ "model": "sdxl-turbo", "prompt": "a cat in a hat, studio lighting", "n": 1, "size": "1024x1024", "response_format": "url" }'Request fields honoured:
| Field | Default | Notes |
|---|---|---|
model | sdxl-turbo | Must be a curated image model. Built-ins: sdxl-turbo, sd-1.5-pruned-emaonly. |
prompt | — | Required. Empty prompt → 422 (image.prompt_required). |
n | 1 | Batch size. |
size | slot default | WxH, e.g. 1024x1024. Falls back to the img slot’s [image] default_size. |
response_format | url | url or b64_json. |
A hal0 extension extra_body accepts seed, steps, cfg, and
negative_prompt.
A model that isn’t in the curated image catalogue returns 404
(image.model_not_curated).
The response is the OpenAI image shape:
{ "created": 1716000000, "data": [ { "url": "/api/images/cache/<uuid>.png" } ], "_hal0": { "...debug meta from the workflow translator..." }}With response_format: "b64_json" each data entry carries a base64 PNG
in b64_json instead of a url.
See also
Section titled “See also”- Manage slots — the
imgslot lifecycle. - Configure — set
[image]slot defaults (default_size,default_steps,idle_restore_minutes). - Observe the system — tail
hal0-slot@img.