Devices, providers & profiles
A hal0 slot is described by three orthogonal facts: a device (the hardware preference), a provider (the inference runtime label), and a profile (a reusable container template — image plus bench-tuned flags). This page is the authoritative reference for the valid values of each and how they connect.
Devices
Section titled “Devices”device carries hardware intent only. It is validated at config-load time —
a typo raises a ValidationError with the field path.
device | Hardware | Default provider |
|---|---|---|
gpu-rocm | AMD GPU via ROCm | llama-server |
gpu-vulkan | Any GPU via Vulkan | llama-server |
cpu | CPU-only fallback | llama-server |
npu | AMD XDNA NPU via FastFlowLM | flm |
gpu-rocm is the package-level default device constant, but the hardware
recommender actively steers Strix Halo (unified memory) installs to gpu-vulkan
for broader compatibility. The recommender may also select cpu or npu on
hosts without ROCm support.
Providers
Section titled “Providers”provider is the runtime label round-tripped on each slot. Every slot runs as
a podman container regardless of provider; the field exists for UI labels and
backwards compatibility.
provider | Runtime | Typical slot types |
|---|---|---|
llama-server | llama.cpp server (ROCm / Vulkan / CPU) | chat, embed, rerank |
flm | FastFlowLM on the NPU | chat / stt / embed (one process, trio) |
kokoro | Kokoro-82M text-to-speech (ONNX) | tts |
comfyui | ComfyUI image generation | image |
Seed profiles
Section titled “Seed profiles”Profiles live in /etc/hal0/profiles.toml. When that file is absent, hal0
serves the built-in seed catalog below, so GET /api/profiles is always
populated on a fresh install. A profile supplies the container image, the
bench-tuned flag bundle, and an optional MTP toggle; the slot supplies the
model, context size, and port.
| Profile | device_class | Image | MTP | Intent |
|---|---|---|---|---|
rocm | gpu | ghcr.io/hal0ai/amd-strix-halo-toolboxes:rocm-7.2.4-rocmfp4-server | off | MoE agents · q8 KV |
rocm-dnse | gpu | ghcr.io/hal0ai/amd-strix-halo-toolboxes:rocm-7.2.4-rocmfp4-server | on | Dense + MTP · q4 KV |
rocm-moe | gpu | ghcr.io/hal0ai/amd-strix-halo-toolboxes:rocm-7.2.4-rocmfp4-server | on | MoE + MTP · q4 KV |
vulkan | gpu | ghcr.io/hal0ai/amd-strix-halo-toolboxes:vulkan-radv-server | off | Vulkan std · fallback |
flm | npu | ghcr.io/hal0ai/hal0-toolbox-flm:0.9.43 | off | FLM NPU inference |
tts | cpu | ghcr.io/hal0ai/hal0-toolbox-kokoro:v1 | off | TTS · Kokoro |
comfyui | img | docker.io/kyuz0/amd-strix-halo-comfyui@sha256:0066678ae9043f69… | off | Image generation |
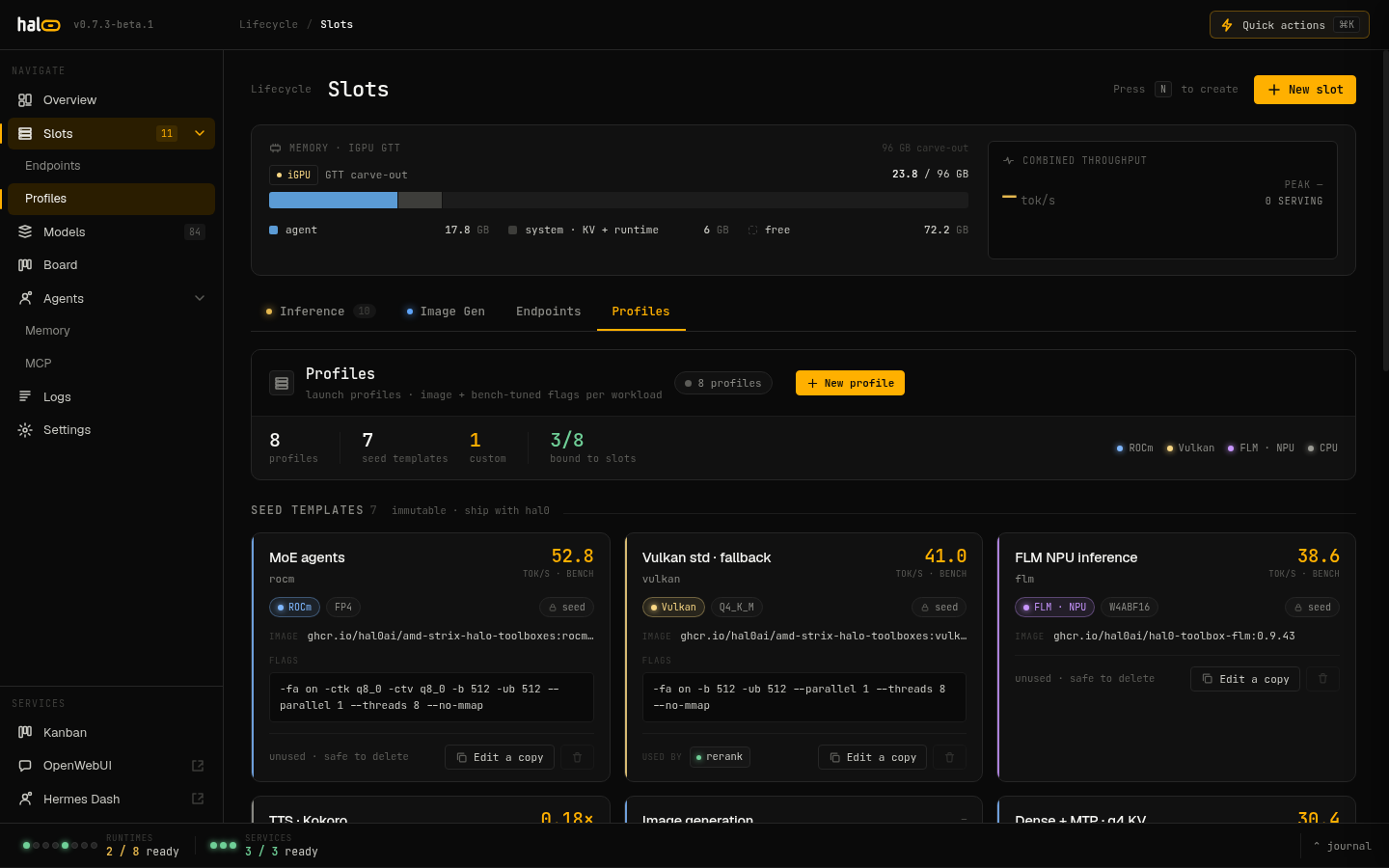 Profiles tab in the hal0 dashboard — seed profile cards display device class, quantisation, and bench throughput (tokens/sec or RTF).
Profiles tab in the hal0 dashboard — seed profile cards display device class, quantisation, and bench throughput (tokens/sec or RTF).
MTP flag bundle
Section titled “MTP flag bundle”When a profile’s effective MTP setting is on (profile mtp = true, or a slot’s
mtp = true override), the multi-token-prediction draft-speculation flag bundle
is appended after the profile flags at resolve time. A slot’s mtp field
(true / false / unset-to-inherit) overrides the profile default.
Device-to-default-profile map
Section titled “Device-to-default-profile map”The create-slot device picker and legacy-slot migration use this map to choose a starting profile per device class:
device | Default profile |
|---|---|
gpu-rocm | rocm |
gpu-vulkan | vulkan |
cpu | tts |
npu | flm |
Toolbox images
Section titled “Toolbox images”Toolbox images are pinned per hal0 release in manifest.json (by short name →
canonical ref plus a sha256 digest). They are public on ghcr.io/hal0ai/; the
installer pulls them anonymously. An empty digest means the image is unpublished
for that release and the runtime pulls by tag with a warning.
| Short name | Image ref (current release) | Notes |
|---|---|---|
vulkan | ghcr.io/hal0ai/amd-strix-halo-toolboxes:vulkan-radv-server | llama.cpp Vulkan backend |
rocm | ghcr.io/hal0ai/amd-strix-halo-toolboxes:rocm-7.2.4-rocmfp4-server | llama.cpp ROCm backend |
flm | ghcr.io/hal0ai/hal0-toolbox-flm:0.9.43 | FastFlowLM on AMD XDNA2 NPU |
kokoro | ghcr.io/hal0ai/hal0-toolbox-kokoro:v1 | Kokoro-82M TTS (CPU ONNX) |
comfyui | docker.io/kyuz0/amd-strix-halo-comfyui@sha256:0066678ae9043f69a1c8c7699e70626ceffd35c1a8ca03227a05640ad0241ed2 | ComfyUI image generation |
See also
Section titled “See also”- Hardware matrix — what runs on each device and the backend availability order.
- Config schema — the full slot TOML, profile, and
hal0.tomlfield reference. - Paths & files — where
profiles.toml, slot TOMLs, andmanifest.jsonlive.