Hardware matrix
hal0 targets AMD APU/GPU plus the AMD XDNA NPU, with a CPU fallback that is always available. This page lists what runs on each accelerator and the order hal0 prefers them in.
Hardware targets
Section titled “Hardware targets”| Target | Backend / runtime | What runs there |
|---|---|---|
| AMD GPU (ROCm) | llama.cpp ROCm | chat / embed / rerank LLM inference (highest tps) |
| AMD GPU (Vulkan) | llama.cpp Vulkan | chat / embed / rerank LLM inference (broad-compat) |
| AMD XDNA NPU | FastFlowLM (FLM) | chat + speech-to-text + embeddings (one process) |
| CPU | llama.cpp / ONNX | fallback LLM inference; Kokoro TTS |
The reference platform is AMD Strix Halo: an 8060S-class iGPU, an XDNA NPU, and a unified-memory pool the GPU shares with the host via GTT. hal0’s profile flags are bench-tuned for that target, but the GPU/Vulkan and CPU paths run on any modern Linux AMD system.
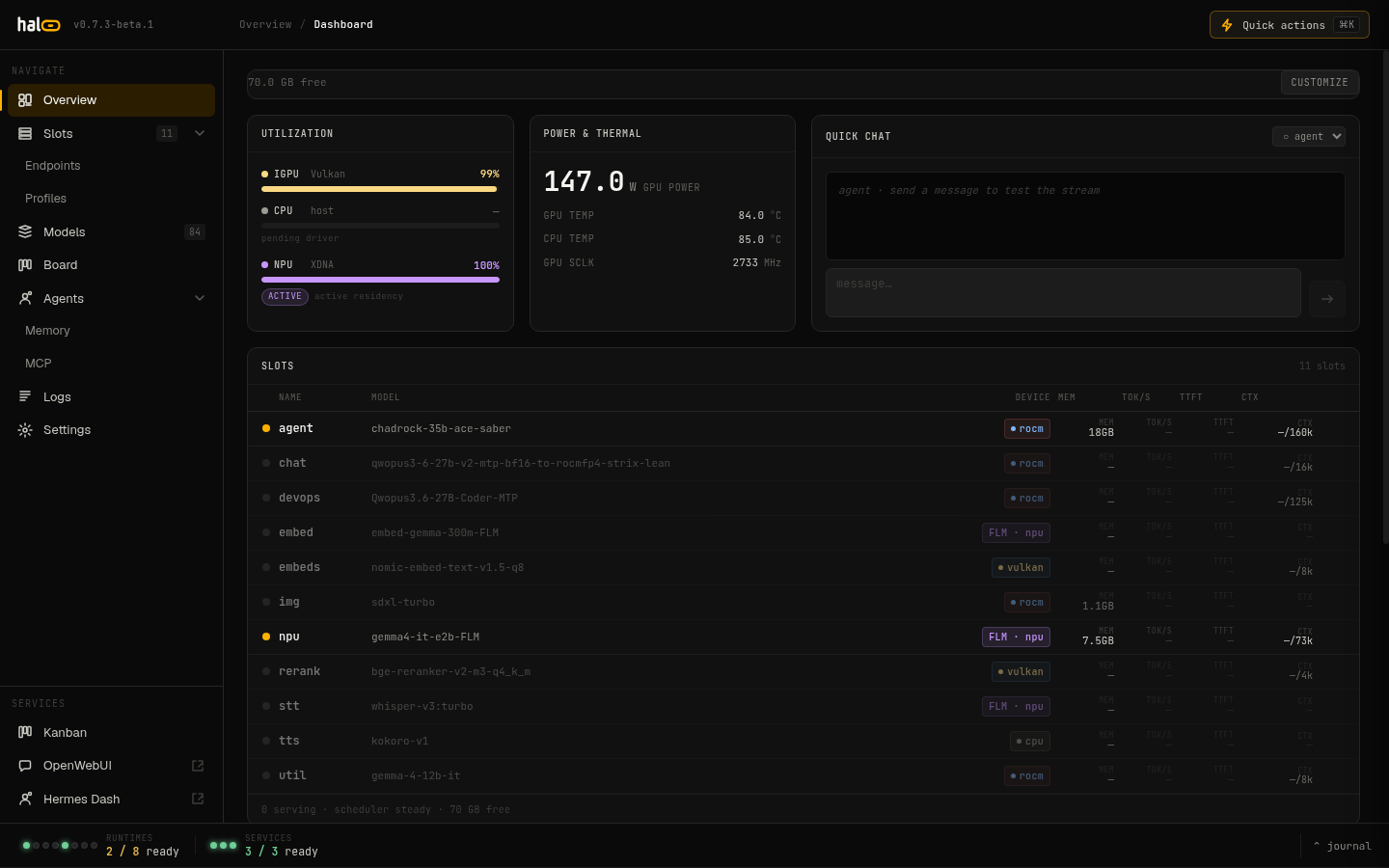 Hardware monitoring dashboard for GPU, NPU, and system memory.
Hardware monitoring dashboard for GPU, NPU, and system memory.
Backend availability order
Section titled “Backend availability order”hal0 probes the host and advertises the backends it can actually run, in this order:
- NPU — only when an XDNA NPU is present and the FLM toolbox image is already pulled locally.
- GPU (Vulkan) — whenever a GPU is detected (every modern Linux GPU has Mesa Vulkan).
- GPU (ROCm) — only when the detected GPU is an AMD GPU with compute
support (
compute_capable). - CPU — always reachable; the guaranteed fallback.
| Backend id | Label | Provider | Multiplex | Advertised when |
|---|---|---|---|---|
npu | NPU | flm | yes | XDNA present + FLM image pulled |
gpu-vulkan | GPU (Vulkan) | llama-server | no | any GPU detected |
gpu-rocm | GPU (ROCm) | llama-server | no | AMD GPU with ROCm compute support |
cpu | CPU | llama-server | no | always |
The NPU is multiplex: a single flm serve process answers chat, STT, and
embeddings at once, so one NPU slot can back three capabilities.
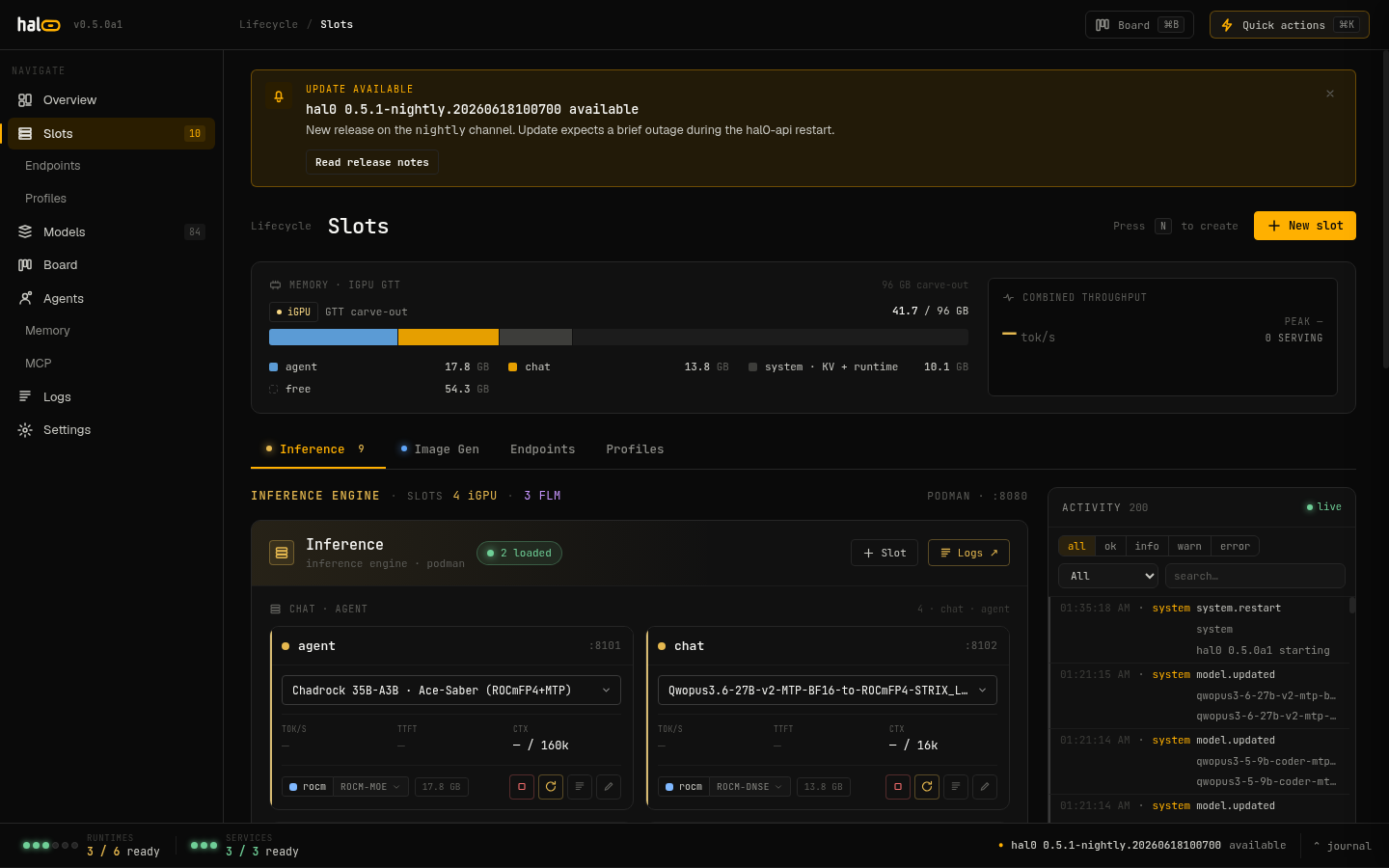 The Inference Engine slot inventory — here
The Inference Engine slot inventory — here 4 iGPU · 3 FLM — with the shared iGPU GTT carve-out above it.
NPU host requirements
Section titled “NPU host requirements”The NPU path runs FastFlowLM in a container, but the host must provide the XDNA driver and firmware:
- the
amdxdnakernel driver (in-tree on kernel ≥ 6.14, or via theamdxdna-dkmspackage on kernel ≥ 6.10), and - NPU firmware ≥ 1.1.0.0.
See also
Section titled “See also”- Devices, providers & profiles — the device → profile → image matrix.
- NPU & power REST routes —
/api/npu,/api/backends,/api/stats/hardware.