Pull and register models
hal0 keeps a local model registry — a record of every model it knows about, where its bytes live, and what it can do. You populate it two ways: pull from Hugging Face, or register a file you already have on disk.
Pull from Hugging Face
Section titled “Pull from Hugging Face”hal0 model pull qwen3-4bThe argument is either a curated alias (see Choose models) or a model id already in the registry. The CLI starts a background pull on the daemon, then polls and renders a progress bar until the job finishes.
The pull lifecycle
Section titled “The pull lifecycle”A pull is a background job with a small state machine:
queued → running → completed ↘ failed ↘ cancelledThe downloader streams the GGUF straight from
https://huggingface.co/<repo>/resolve/main/<file> into a tempfile,
computing SHA-256 as it goes, then atomically moves it into place and
upserts the registry entry with the size and integrity digest. Because
the temp staging dir lives on the same filesystem as the final path, the
install is a true atomic rename even for multi-GB files.
Progress, status, and cancel
Section titled “Progress, status, and cancel”The CLI handles progress for you, but the underlying API is available directly:
# kick off the pullcurl -X POST http://localhost:8080/api/models/qwen3-4b/pull
# poll statuscurl http://localhost:8080/api/models/qwen3-4b/pull/status
# live SSE progresscurl -N http://localhost:8080/api/models/qwen3-4b/pull/stream
# cancel an in-flight pullcurl -X POST http://localhost:8080/api/models/qwen3-4b/pull/cancelThe status payload carries state, bytes_downloaded, bytes_total,
sha256, path, and (on failure) error / error_code. Cancellation
sets a flag the background task observes on the next chunk boundary; the
partial download is unlinked and the job transitions to cancelled.
Pulls are de-duplicated: POSTing a pull for a model already queued or
running returns the existing job handle instead of starting a second
download.
Pull by Hugging Face coordinates
Section titled “Pull by Hugging Face coordinates”To pull a file that isn’t in the curated catalogue, supply the repo and filename in the body. hal0 seeds a registry row for the new id so the dashboard can track progress, then pulls:
curl -X POST http://localhost:8080/api/models/my-qwen-build/pull \ -H 'content-type: application/json' \ -d '{"hf_repo":"unsloth/Qwen3.6-27B-GGUF","hf_filename":"Qwen3.6-27B-UD-Q5_K_XL.gguf","labels":["chat"]}'Search and inspect Hugging Face
Section titled “Search and inspect Hugging Face”hal0 proxies HF’s public search and a per-repo inspector so you can find a model and see its pullable variants without leaving your host.
# free-text search (capped at 20 rows)curl 'http://localhost:8080/api/hf/search?q=qwen3+gguf&type=text-generation'
# inspect a repo: list its GGUF variants + license + README excerptcurl -X POST http://localhost:8080/api/models/inspect \ -H 'content-type: application/json' \ -d '{"hf_repo":"unsloth/Qwen3-8B-GGUF"}'Inspect returns each .gguf file as a variant with its real LFS byte
size; use a variant’s id (the filename) as hf_filename when you pull.
Register a file already on disk
Section titled “Register a file already on disk”If the bytes are already on the host — say you dropped a GGUF into the model store — register it without re-downloading:
hal0 model register qwen3-4b-q4_k_m \ --path /path/to/qwen3-4b-instruct-q4_k_m.gguf \ --name "Qwen3 4B Q4_K_M" \ --license Apache-2.0The file must be readable by the hal0-api process; hal0 records metadata,
it does not copy or chown. The API also exposes a one-shot
“add by path” flow (POST /api/models/add-from-path) and a directory
scan (POST /api/models/scan) that auto-detects capabilities and backends
from each file.
List, inspect, and remove
Section titled “List, inspect, and remove”hal0 model listhal0 model list --jsonAggregates the local registry with everything advertised by configured
upstreams. Local files win on id collision and are flagged installed.
hal0 model show qwen3-4bhal0 model show qwen3-4b --jsonhal0 model rm qwen3-4bRemoves the registry row (confirm prompt; --force to skip). The bytes on
disk are never touched — that’s your call. If a slot has this model as its
default, the API cascades: it unloads the slot and clears the default.
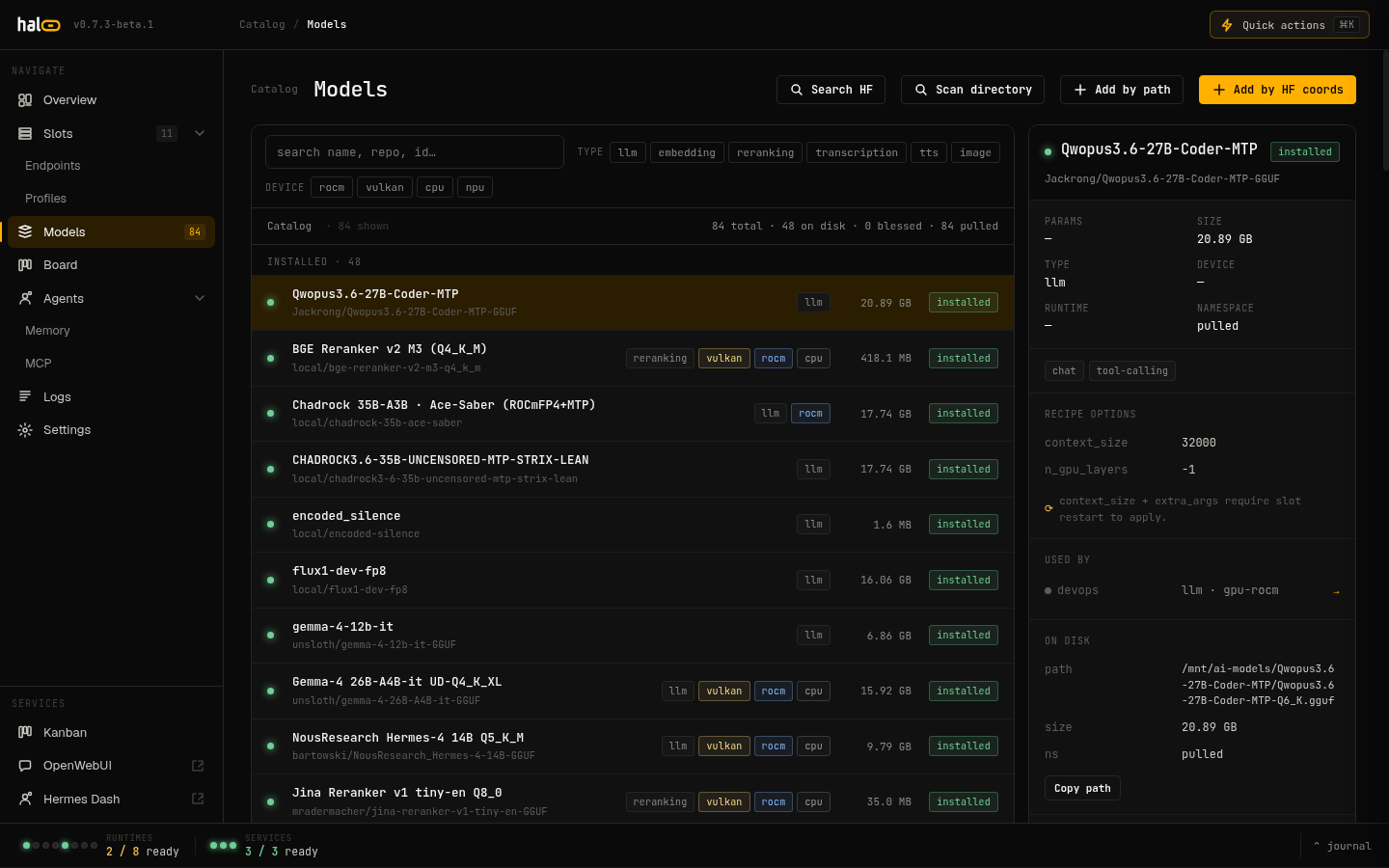 The Models tab lists every installed and upstream-advertised model, with pull-state badges for in-flight downloads.
The Models tab lists every installed and upstream-advertised model, with pull-state badges for in-flight downloads.
Assign a model to a slot
Section titled “Assign a model to a slot”hal0 model assign qwen3.5-9b --slot chatThis sets the slot’s default model but does not load it — follow with
hal0 slot load chat (see
Manage slots).
The registry on disk
Section titled “The registry on disk”Registry entries are metadata records — id, display name, path, size, SHA-256, capabilities, and the Hugging Face coordinates a pull came from. The registry is the source of truth the dispatcher resolves model ids against; the actual weights live in your configured model store.