Radeon iGPU
The integrated GPU runs LLM and image workloads through either ROCm
(gpu-rocm) or Vulkan (gpu-vulkan). It’s detected as an AMD amdgpu
device; the marketing name comes from the system at probe time.
hal0 is hardware-agnostic in principle, but it is designed around one reference platform: AMD’s Ryzen AI Max+ (“Strix Halo”). This is an APU that pairs a capable Radeon iGPU and an XDNA NPU with a large pool of memory shared between the CPU and GPU. Understanding that shape explains most of hal0’s design — the GPU arbiter, the device choices, and the way memory is reported.
A Strix Halo machine gives hal0 three places to run a model:
Radeon iGPU
The integrated GPU runs LLM and image workloads through either ROCm
(gpu-rocm) or Vulkan (gpu-vulkan). It’s detected as an AMD amdgpu
device; the marketing name comes from the system at probe time.
XDNA NPU
The AMD XDNA NPU is driven by FastFlowLM (FLM) on the npu device. hal0
detects it via the amdxdna driver (the /dev/accel device nodes), and one
flm serve process serves the NPU trio — chat, STT, and embeddings.
CPU
The Ryzen CPU is always available as the cpu device and is the home for
CPU-only runtimes such as text-to-speech.
These map directly to hal0’s device enum: gpu-rocm, gpu-vulkan, npu, and
cpu. See Capabilities & profiles
for how a slot picks one.
The iGPU can run through two backends, and hal0 treats them as distinct devices because they behave differently:
gpu-rocm) — AMD’s compute stack. hal0 tests for it by probing for
the ROCm tooling; the GPU is marked compute-capable when it’s present. ROCm
can deliver the best throughput, but it depends on a matching kernel and
user-space combination.gpu-vulkan) — the broad-compatibility path via Mesa, which ships
with the amdgpu driver. It works on essentially any AMD GPU without extra
setup, which makes it the safe default for unified-memory APUs.The defining feature of Strix Halo — and the reason it’s such a good fit for local inference — is unified memory. The iGPU doesn’t have a large dedicated VRAM bank; instead it shares the system’s RAM through a GTT pool. A single large memory pool can be handed to whichever engine needs it, so you can load models far larger than a typical discrete GPU’s VRAM would allow.
This shapes how hal0 reports memory. It does not add system RAM to GPU VRAM, because on a unified-memory APU that would double-count — the GPU’s memory is host RAM shared via GTT. Instead the probe derives a single unified-memory pool figure and surfaces that as the headroom you actually have. (hal0 detects the unified-memory shape by recognising the tiny VRAM carve-out alongside a large GTT pool; on a discrete GPU it reports VRAM and RAM separately.) When running inside a container or VM with a memory cap, hal0 also reads the cgroup limit and treats it as a third constraint, so the reported headroom reflects what you can really use.
Because one pool is shared, two GPU workloads can’t both hold their weights at once. That’s exactly why the GPU arbiter exists: it gives the GPU’s memory to either the LLM slots or the image slot, one group at a time, rather than letting them fight over the pool.
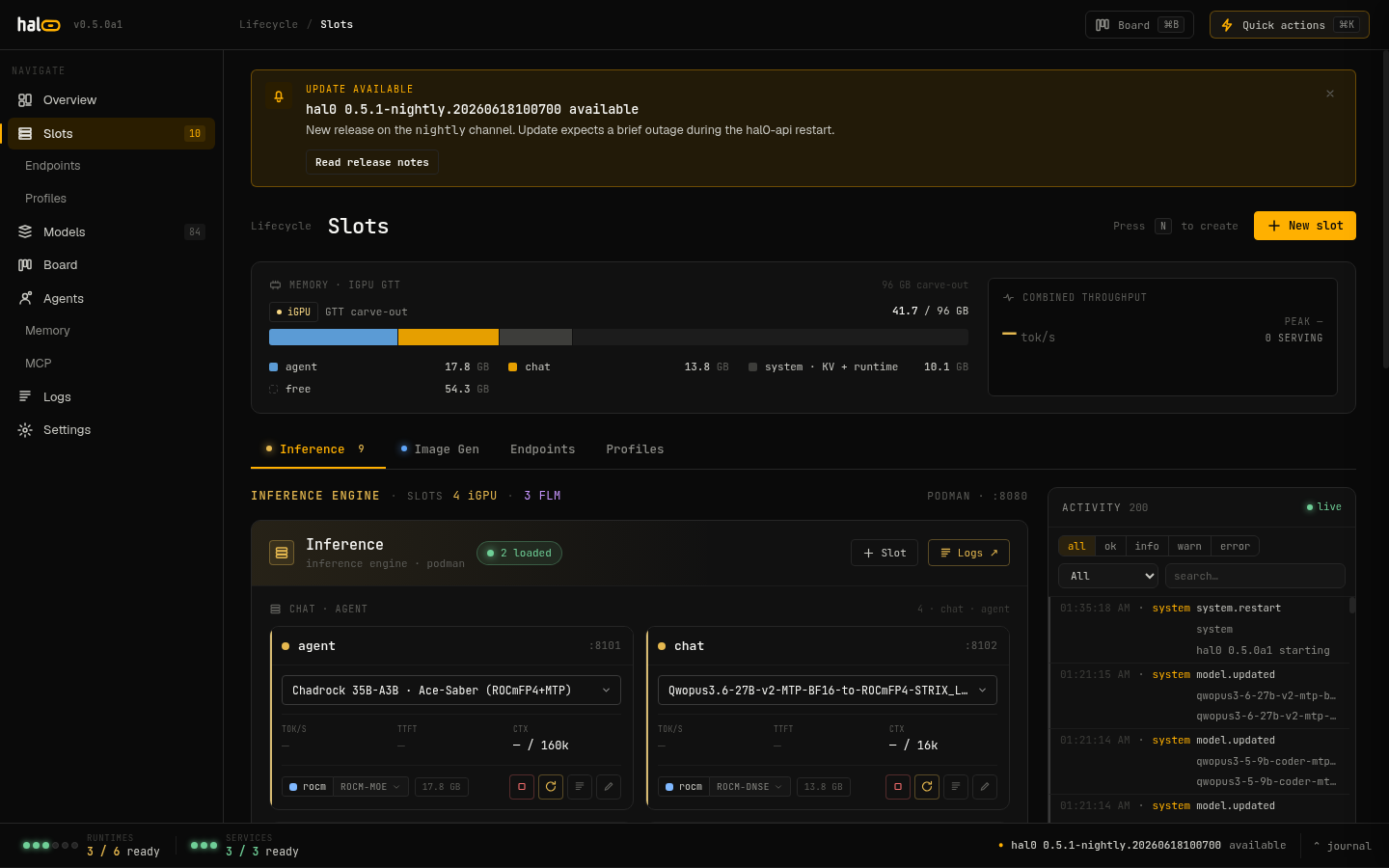 The shared GTT carve-out above the Inference Engine — iGPU slots and FLM (NPU) slots both draw from one unified-memory pool.
The shared GTT carve-out above the Inference Engine — iGPU slots and FLM (NPU) slots both draw from one unified-memory pool.
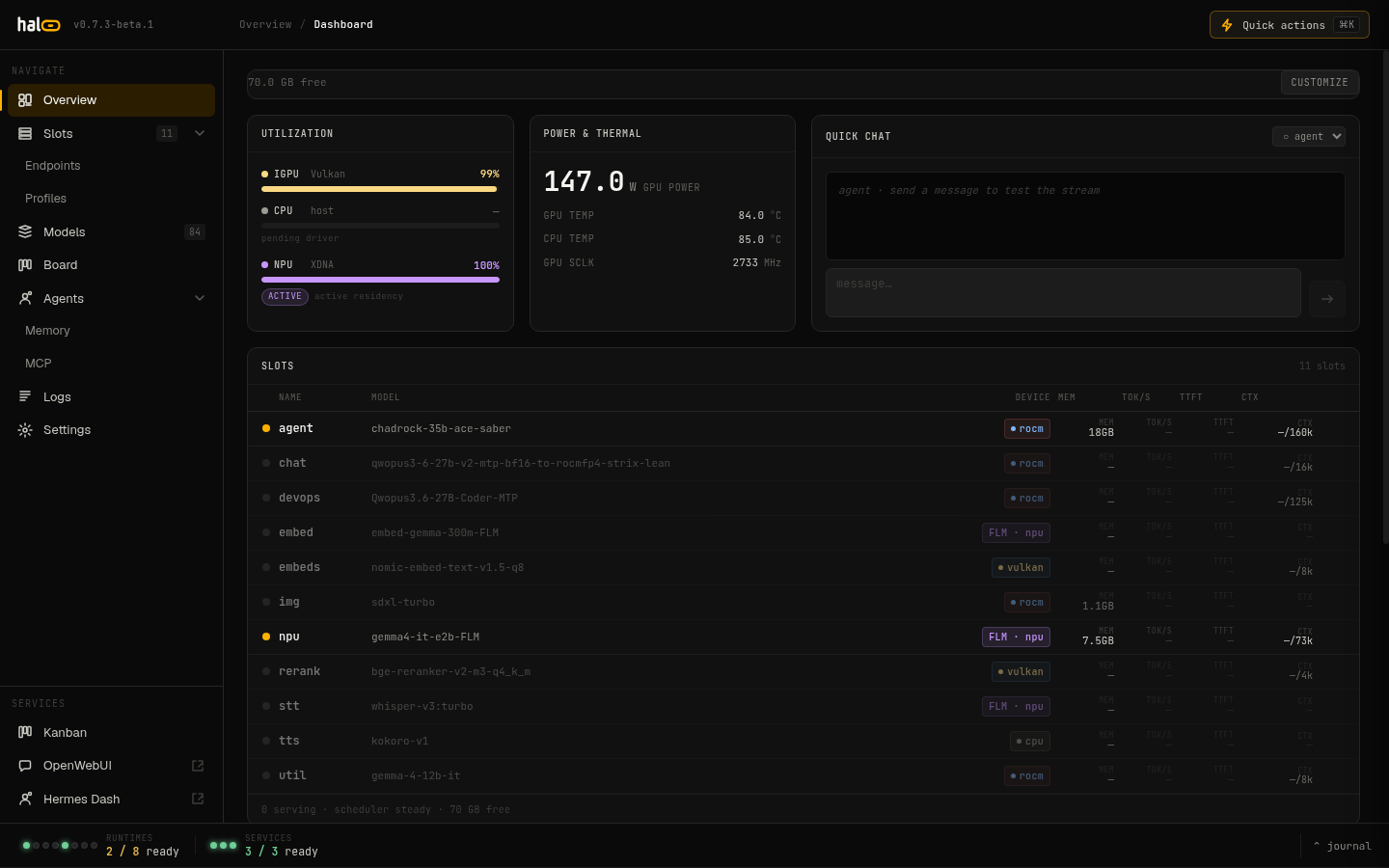 The hardware dashboard panel after a successful probe run.
The hardware dashboard panel after a successful probe run.
hal0 ships a hardware probe that inspects the machine and writes the result for
the rest of the system to read. It detects the CPU (model, cores, threads),
system RAM and available memory, the GPU(s) and their ROCm/Vulkan capability,
the NPU (presence, vendor, driver), the unified-memory pool, any cgroup memory
cap, and free disk space. It also classifies the platform — strix-halo is
its own value, alongside generic ones such as bare-metal-amd-gpu, lxc,
kvm, wsl2, and unknown — and the dashboard uses that to label memory as
“unified” only on the platforms where that’s true.