hal0 documentation
hal0 turns a Linux box into a polished, OpenAI-compatible inference appliance. It is built for the AMD Ryzen AI Max+ 395 (“Strix Halo”) — iGPU + XDNA NPU + 128 GB of unified memory — and falls back to portable hardware parsers on every other host.
Every inference workload runs as its own podman container, supervised
by a hal0-slot@<name>.service systemd unit. A single control plane,
hal0-api on port 8080, owns the slot state machines, dispatches
OpenAI-compatible /v1/* requests to the right slot, and serves the
dashboard. There is no shared inference daemon to babysit.
What you get
Section titled “What you get”- OpenAI-compatible
/v1/*API — chat, completions, embeddings, rerank, audio transcription, speech, and image generation. Point any OpenAI SDK athttp://localhost:8080/v1and go. - Hardware-aware slots — each capability gets its own container, image, flags, port, and lifecycle, sharing only the GPU through an arbiter.
- First-run terminal setup — the
hal0 setupTUI picks a hardware-anchored tier and provisions a coherent set of slots, models, and extensions. - Prewired chat UI — OpenWebUI on port
3001, zero config. - Signed self-update — cosign-verified tarballs with one-flag rollback.
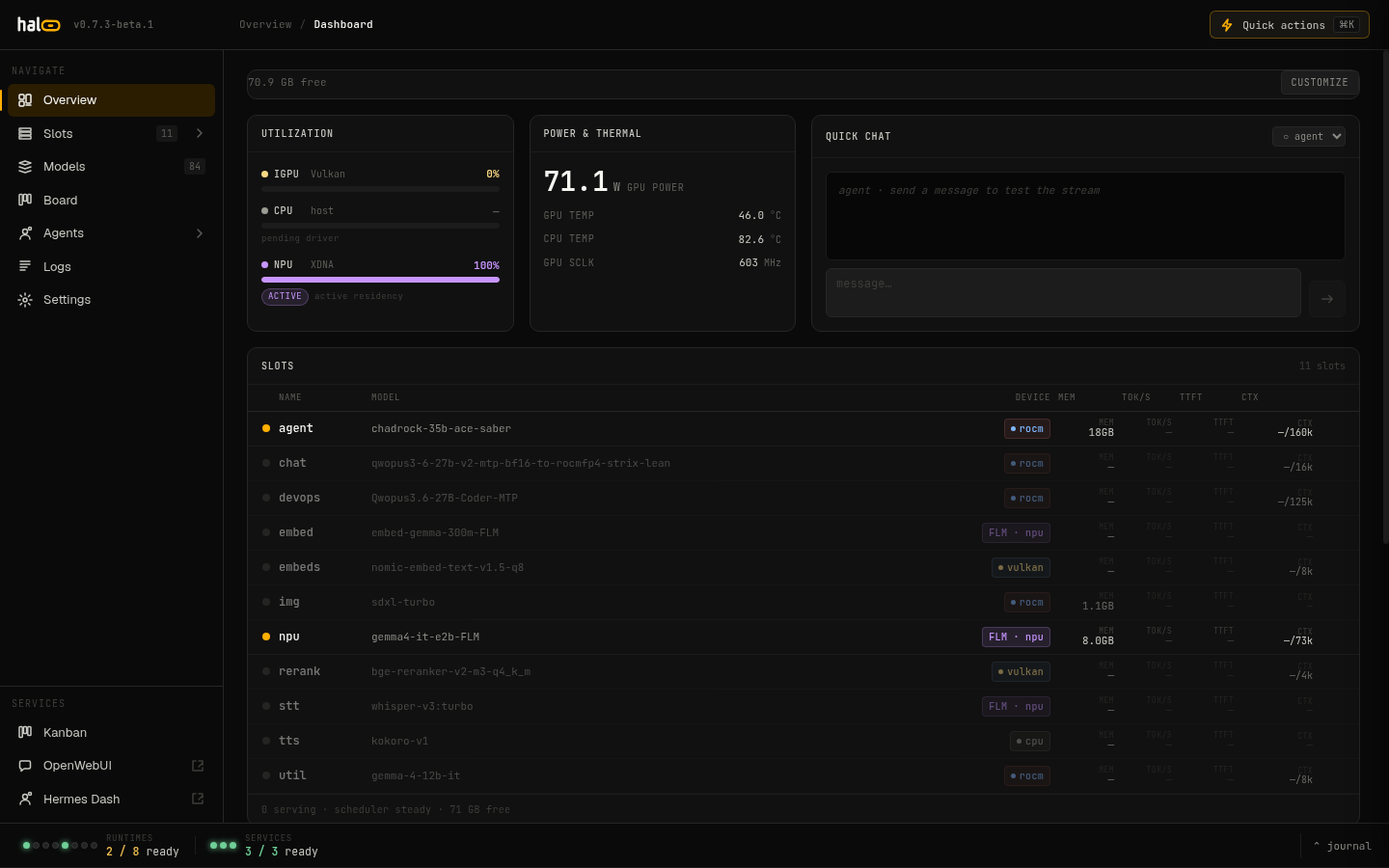 The hal0 dashboard — slot status, hardware metrics, and quick actions.
The hal0 dashboard — slot status, hardware metrics, and quick actions.
Start here
Section titled “Start here” Install hal0 One-line install: fetch, verify, unpack, and bring up the API.
First-run setup Run the hal0 setup TUI to provision your first slots, models, and extensions.
Load your first model Pull a model from Hugging Face and assign it to a slot.
Send your first chat Chat from OpenWebUI or curl the OpenAI-compatible endpoint.